%------------------------ 步骤3 ------------------------ fori = 1:N bi_tilde(:,i) = compute_bi(alpha_tilde,i,N); % 获得bi_tilde end
r = (1/2)*norm(alpha_tilde(:,1)-alpha_tilde(:,2)); % 初始化超球半径 fori = 1:N-1 forj = i+1:N dist_ai_aj(i,j) = norm(alpha_tilde(:,i)-alpha_tilde(:,j)); if (1/2)*dist_ai_aj(i,j) < r r = (1/2)*dist_ai_aj(i,j); % 计算超球半径 end end end Xd_divided_idx = zeros(L,1); % 初始化标记数组 radius_square = r^2; % 半径的平方 for k = 1:N [IDX_alpha_i_tilde]= find( sum( (Xd- alpha_tilde(:,k)*ones(1,L) ).^2,1 ) < radius_square ); Xd_divided_idx(IDX_alpha_i_tilde) = k ; % 计算超球 end
%------------------------ 步骤4 ------------------------ fori = 1:N Hi_idx = setdiff([1:N],[i]); % 除去第i个端元 for k = 1:1*(N-1) Ri_k = Xd(:,( Xd_divided_idx == Hi_idx(k) )); % 选择属于第k个超球的数据 [val idx] = max(bi_tilde(:,i)'*Ri_k); % 找到与bi_tilde(:,i)投影最大的点 pi_k(:,k) = Ri_k(:,idx); % 记录这些点作为超平面上的N-1个仿射独立点 end b_hat(:,i) = compute_bi([pi_k alpha_tilde(:,i)],N,N); % 计算b_hat(:,i) h_hat(i,1) = max(b_hat(:,i)'*Xd); % 计算h_hat(i,1) end
%% 子程序1 function[bi] = compute_bi(a0,i,N) Hindx = setdiff([1:N],[i]); % 除去第i个端元 A_Hindx = a0(:,Hindx); % 选择其他端元 A_tilde_i = A_Hindx(:,1:N-2)-A_Hindx(:,N-1)*ones(1,N-2); % 计算A_tilde_i bi = A_Hindx(:,N-1)-a0(:,i); % 计算bi bi = (eye(N-1) - A_tilde_i*(pinv(A_tilde_i'*A_tilde_i))*A_tilde_i')*bi; % 投影bi到null(A_tilde_i) bi = bi/norm(bi); % 归一化 return; % end
%% 子程序2 function[alpha_tilde] = SPA(Xd,L,N)
% 参考文献: % [1] W.-K. Ma, J. M. Bioucas-Dias, T.-H. Chan, N. Gillis, P. Gader, A. J. Plaza, A. Ambikapathi, and C.-Y. Chi, % ``A signal processing perspective on hyperspectral unmixing,�� % IEEE Signal Process. Mag., vol. 31, no. 1, pp. 67�V81, 2014. % % [2] S. Arora, R. Ge, Y. Halpern, D. Mimno, A. Moitra, D. Sontag, Y. Wu, and M. Zhu, % ``A practical algorithm for topic modeling with provable guarantees,�� % arXiv preprint arXiv:1212.4777, 2012. %====================================================================== % 连续投影算法(SPA)的实现 % [alpha_tilde] = SPA(Xd,L,N) %====================================================================== % 输入 % Xd是降维后的数据矩阵 % L是像素数 % N是端元数量 %---------------------------------------------------------------------- % 输出 % alpha_tilde是(N-1)-by-N矩阵,其列是降维后的最纯像素 %====================================================================== %======================================================================
# Reference: # C.-H. Lin, C.-Y. Chi, Y.-H. Wang, and T.-H. Chan, # ``A fast hyperplane-based minimum-volume enclosing simplex algorithm for blind hyperspectral unmixing," # arXiv preprint arXiv:1510.08917, 2015. #====================================================================== # A fast implementation of Hyperplane-based Craig-Simplex-Identification algorithm # [A_est, S_est, time] = HyperCSI(X,N) #====================================================================== # Input # X is M-by-L data matrix, where M is the number of spectral bands and L is the number of pixels. # N is the number of endmembers. #---------------------------------------------------------------------- # Output # A_est is M-by-N mixing matrix whose columns are estimated endmember signatures. # S_est is N-by-L source matrix whose rows are estimated abundance maps. # time is the computation time (in secs). #========================================================================
defHyperCSI(X, N): t0 = time()
#------------------------ Step 1 ------------------------ M, L = X.shape d = np.mean(X, axis=1, keepdims=True) U = X - d D, eV = np.linalg.eigh(U @ U.T) C = eV[:, M-N:M] Xd = C.T @ (X - d) # dimension reduced data (Xd is (N-1)-by-L)
#------------------------ Step 3 ------------------------ bi_tilde = np.zeros((N-1, N)) for i inrange(N): bi_tilde[:, i] = compute_bi(alpha_tilde, i, N) # obtain bi_tilde
r = 0.5 * np.linalg.norm(alpha_tilde[:, 0] - alpha_tilde[:, 1]) for i inrange(N-1): for j inrange(i+1, N): dist_ai_aj = np.linalg.norm(alpha_tilde[:, i] - alpha_tilde[:, j]) if0.5 * dist_ai_aj < r: r = 0.5 * dist_ai_aj # compute radius of hyperballs
Xd_divided_idx = np.zeros(L, dtype=int) radius_square = r**2 for k inrange(N): IDX_alpha_i_tilde = np.sum((Xd - alpha_tilde[:, k].reshape(-1, 1))**2, axis=0) < radius_square Xd_divided_idx[IDX_alpha_i_tilde] = k # compute the hyperballs
#------------------------ Step 4 ------------------------ b_hat = np.zeros((N-1, N)) h_hat = np.zeros(N) for i inrange(N): Hi_idx = [idx for idx inrange(N) if idx != i] pi_k = np.zeros((N-1, N-1)) for k inrange(N-1): Ri_k = Xd[:, Xd_divided_idx == Hi_idx[k]] idx = np.argmax(bi_tilde[:, i].T @ Ri_k) pi_k[:, k] = Ri_k[:, idx] # find N-1 affinely independent points for each hyperplane b_hat[:, i] = compute_bi(np.hstack((pi_k, alpha_tilde[:, i].reshape(-1, 1))), N, N) h_hat[i] = np.max(b_hat[:, i].T @ Xd)
#------------------------ Step 5 & Step 6 ------------------------ comm_flag = 1 # comm_flag = 1 in noisy case: bring hyperplanes closer to the center of data cloud # comm_flag = 0 when no noise: Step 5 will not be performed (and hence c = 1)
eta = 0.9# 0.9 is empirically good choice for endmembers in USGS library alpha_hat = np.zeros((N-1, N)) for i inrange(N): bbbb = np.delete(b_hat, i, axis=1) ccconst = np.delete(h_hat, i) alpha_hat[:, i] = np.linalg.pinv(bbbb.T) @ ccconst
if comm_flag == 1: VV = C @ alpha_hat UU = d * np.ones((1, N)) closed_form_optval = max(1, np.max((-VV) / UU)) # c' in Step 5 c = closed_form_optval / eta h_hat = h_hat / c alpha_hat = alpha_hat / c
A_est = C @ alpha_hat + d # endmemeber estimates
#------------------------ Step 7 ------------------------ # Step 7 can be removed if the user do not need abundance estimation S_est = (h_hat.reshape(1, -1) - b_hat.T @ Xd) / ((h_hat - np.sum(b_hat * alpha_hat, axis=1)).reshape(1, -1)) S_est = np.maximum(S_est, 0) # end
time_elapsed = time() - t0
return A_est, S_est, time_elapsed
#% subprogram 1 defcompute_bi(a0, i, N): Hindx = [idx for idx inrange(N) if idx != i] A_Hindx = a0[:, Hindx] A_tilde_i = A_Hindx[:, :-1] - A_Hindx[:, -1].reshape(-1, 1) bi = A_Hindx[:, -1] - a0[:, i] A_tilde_i_pinv = np.linalg.pinv(A_tilde_i.T @ A_tilde_i) bi = (np.eye(N-1) - A_tilde_i @ A_tilde_i_pinv @ A_tilde_i.T) @ bi bi = bi / np.linalg.norm(bi) return bi
#% subprogram 2 defSPA(Xd, L, N): # Reference: # [1] W.-K. Ma, J. M. Bioucas-Dias, T.-H. Chan, N. Gillis, P. Gader, A. J. Plaza, A. Ambikapathi, and C.-Y. Chi, # ``A signal processing perspective on hyperspectral unmixing,�� # IEEE Signal Process. Mag., vol. 31, no. 1, pp. 67�V81, 2014. # # [2] S. Arora, R. Ge, Y. Halpern, D. Mimno, A. Moitra, D. Sontag, Y. Wu, and M. Zhu, # ``A practical algorithm for topic modeling with provable guarantees,�� # arXiv preprint arXiv:1212.4777, 2012. #====================================================================== # An implementation of successive projection algorithm (SPA) # [alpha_tilde] = SPA(Xd,L,N) #====================================================================== # Input # Xd is dimension-reduced (DR) data matrix. # L is the number of pixels. # N is the number of endmembers. #---------------------------------------------------------------------- # Output # alpha_tilde is an (N-1)-by-N matrix whose columns are DR purest pixels. #====================================================================== #======================================================================
#----------- Define default parameters------------------ con_tol = 1e-8# the convergence tolence in SPA num_SPA_itr = N # number of iterations in post-processing of SPA N_max = N # max number of iterations
#------------------------ initialization of SPA ------------------------ A_set = np.zeros((N, 0)) Xd_t = np.vstack((Xd, np.ones(L))) index = [] val = np.sum(Xd_t**2, axis=0) ind = np.argmax(val) A_set = np.hstack((A_set, Xd_t[:, ind].reshape(-1, 1))) index.append(ind) for i inrange(1, N): XX = Xd_t - A_set @ np.linalg.pinv(A_set.T @ A_set) @ A_set.T @ Xd_t val = np.sum(XX**2, axis=0) ind = np.argmax(val) A_set = np.hstack((A_set, Xd_t[:, ind].reshape(-1, 1))) index.append(ind) alpha_tilde = Xd[:, index]
#------------------------ post-processing of SPA ------------------------ current_vol = np.linalg.det(alpha_tilde[:, :-1] - alpha_tilde[:, -1].reshape(-1, 1)) for jjj inrange(num_SPA_itr): b = np.zeros((N-1, N)) for i inrange(N): b[:, i] = compute_bi(alpha_tilde, i, N) b[:, i] = -b[:, i] idx = np.argmax(b[:, i].T @ Xd) alpha_tilde[:, i] = Xd[:, idx] new_vol = np.linalg.det(alpha_tilde[:, :-1] - alpha_tilde[:, -1].reshape(-1, 1)) if (new_vol - current_vol) / current_vol < con_tol: break current_vol = new_vol return alpha_tilde
 设 Craig
的最小外接单纯形为 \(\mathcal{T} =
\mathrm{conv}\{\alpha_1,\dots,\alpha_N\} \subset
\mathbb{R}^{N-1}\)。根据以下命题,这个单纯形可以由 \(N\) 个与之相关的超平面 \(H_1,\dots,H_N\) 确定:
设 Craig
的最小外接单纯形为 \(\mathcal{T} =
\mathrm{conv}\{\alpha_1,\dots,\alpha_N\} \subset
\mathbb{R}^{N-1}\)。根据以下命题,这个单纯形可以由 \(N\) 个与之相关的超平面 \(H_1,\dots,H_N\) 确定: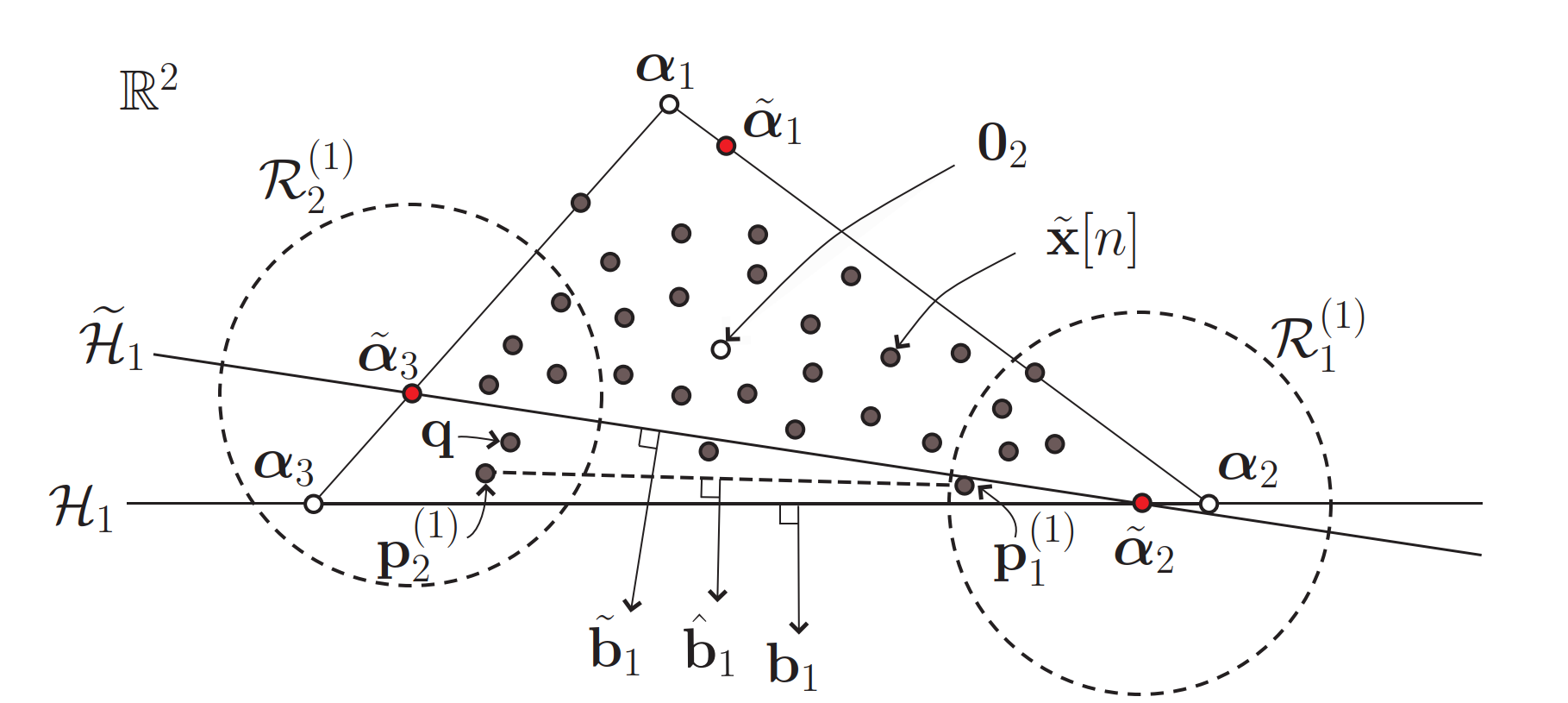 ### 3. 超平面法向量估计
### 3. 超平面法向量估计